一般辨識方法,是針對每一句可辨識語句建立一個 HMM,然後再使用 Viterbi Search 來計算每一個 HMM 的機率值。根據此種方式,我們可以建立一個語句網路(Lexicon Net),來規範 Viterbi Search 計算中,可能產生的辨識語句,主要可以分為三類:
- Linear Net
- Tree Net
- Double-ended Tree Net
以下列可辨識語句為範例:
我們可以產生最簡單的 linear net,圖示如下:
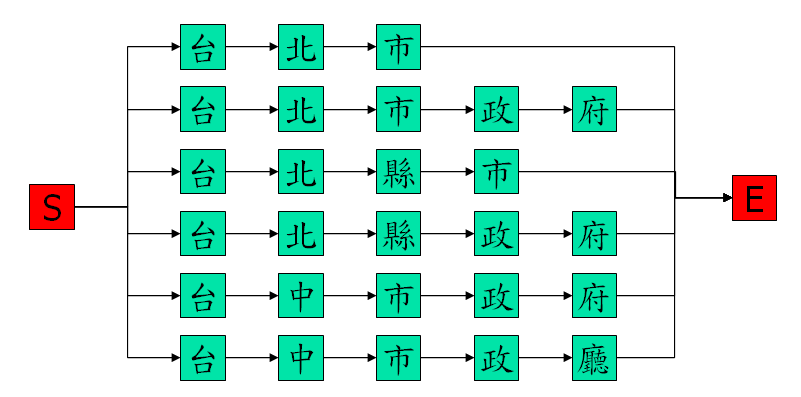 如果將每一條路徑向左對齊,並進行排序,可以找出重複的節點,如下圖之黃色節點:
如果將每一條路徑向左對齊,並進行排序,可以找出重複的節點,如下圖之黃色節點:
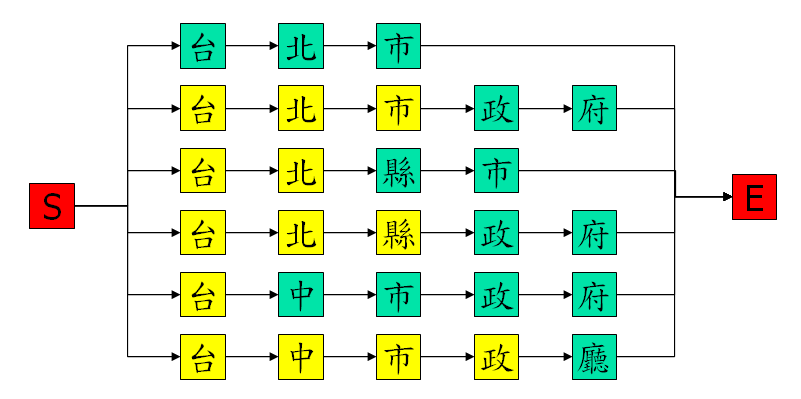 此時我們可以將這些在同一欄且發音相同的黃色節點合併成一個節點,如下:
此時我們可以將這些在同一欄且發音相同的黃色節點合併成一個節點,如下:
 接著,從每一條路徑的尾端來看,我們可以往回走,找出為分叉之前的節點,如下圖之黃色節點:
接著,從每一條路徑的尾端來看,我們可以往回走,找出為分叉之前的節點,如下圖之黃色節點:
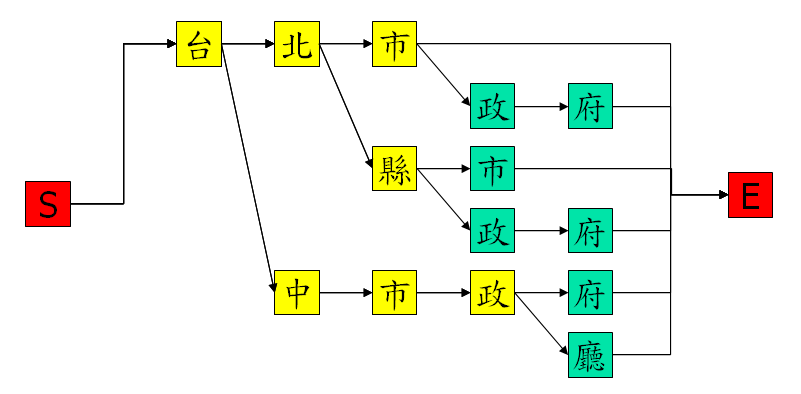
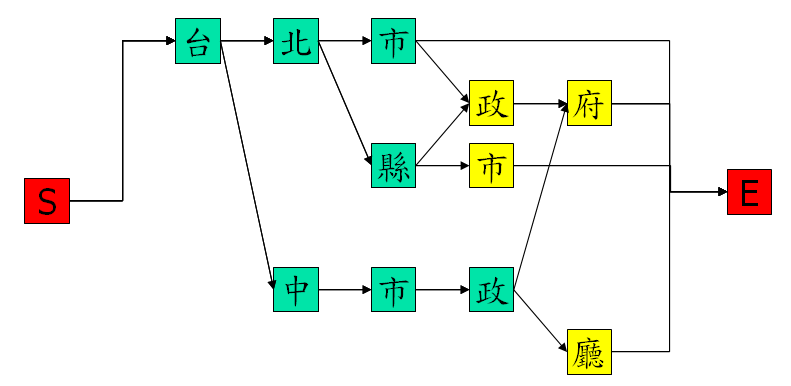
 若從尾端來合併這些節點,可以得到如下圖的 double-ended tree net:
若從尾端來合併這些節點,可以得到如下圖的 double-ended tree net:
 在上述網路結構的簡化過程中,我們必須把握一個原則:簡化後的網路,其所有可能的路徑應該和原來的網路結構相同。換句話說,無論是 linear net、tree net 或是 double-ended tree net,其所有路徑所成的集合是完全一樣的。
在上述網路結構的簡化過程中,我們必須把握一個原則:簡化後的網路,其所有可能的路徑應該和原來的網路結構相同。換句話說,無論是 linear net、tree net 或是 double-ended tree net,其所有路徑所成的集合是完全一樣的。
在上述說明中,我們是將 linear net 中的所有路徑向左對齊來進行排序,如果我們改成向右對齊來進行排序,也可以得到另一組 tree net 及 double-end tree net。
至於是否存在一種網路結構的化簡方法,可以在多項式時間內完成計算,並可以保證擁有最少數目的節點,則目前無法得知。(我對演算法並不熟悉,若讀者有相關資訊,歡迎提供。)
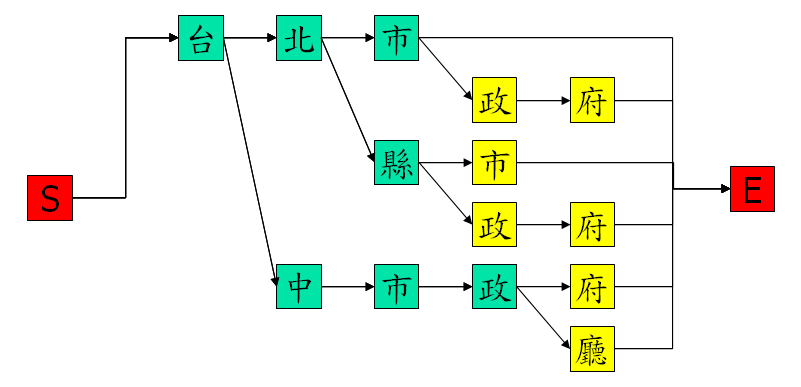
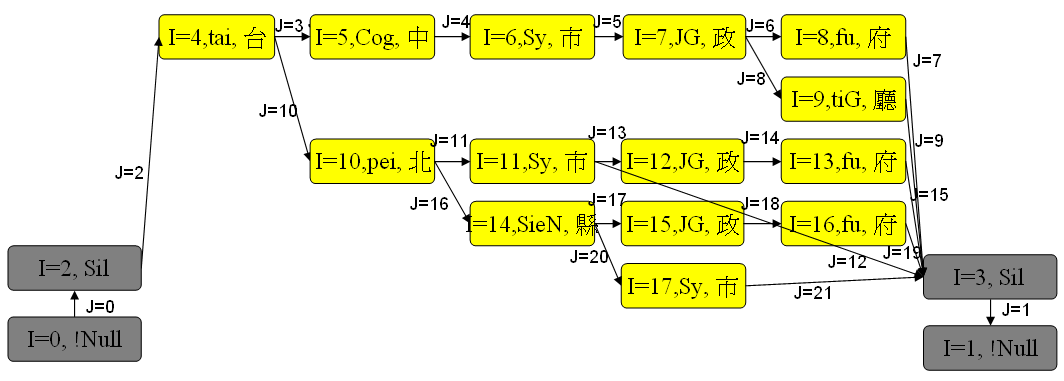
根據上述機關名稱所產生的 tree net,可以表示成下列 net 檔案:
在上述範例中,「N=18」代表有 18 個節點(Nodes),「L=22」代表有 22 條連結(Links),「I=4 W=tai」則是說明第 4 個節點的發音是 tai,「J=16 S=10 E=14」則是記錄第 16 條連結的開始位置是節點 10,結束位置是節點 14,餘類推。相關的圖示如下:
 相關投影片請見此連結。
相關投影片請見此連結。
Audio Signal Processing and Recognition (音訊處理與辨識)
